


In this demonstration, from November 2025 to February 2026, an IOWN APN dedicated line was established between Tokyo (storage) and Fukuoka (GPU), and AI workload performance was measured and evaluated on an AI development infrastructure connecting GPUs and large-capacity storage of “GMO GPU Cloud.” As a result, in training large-scale language models (LLMs), the performance degradation was limited to approximately 0.5% compared to a local environment, confirming that the impact is extremely minimal. For image classification tasks involving data loading, it was also confirmed that, through optimization of training data and other measures, processing at a practical level is possible even in a remote environment. This demonstration proved that practical AI development in a remote distributed environment is achievable through designs tailored to workload characteristics.
Prior to this demonstration, in July 2025, the four companies conducted a pre-demonstration (Phase 1), performing performance tests in a simulated remote environment assuming a Tokyo–Fukuoka distance (approximately 1,000 km), and have published the details as a technical report.
Press release: [https://internet.gmo/news/article/88/](https://internet.gmo/news/article/88/)
Technical report: [https://internet.gmo/news/article/87/](https://internet.gmo/news/article/87/)
The four companies will continue to advance initiatives toward the practical implementation of remote distributed AI infrastructure tailored to customer needs, based on the results of this demonstration.
Background and Purpose
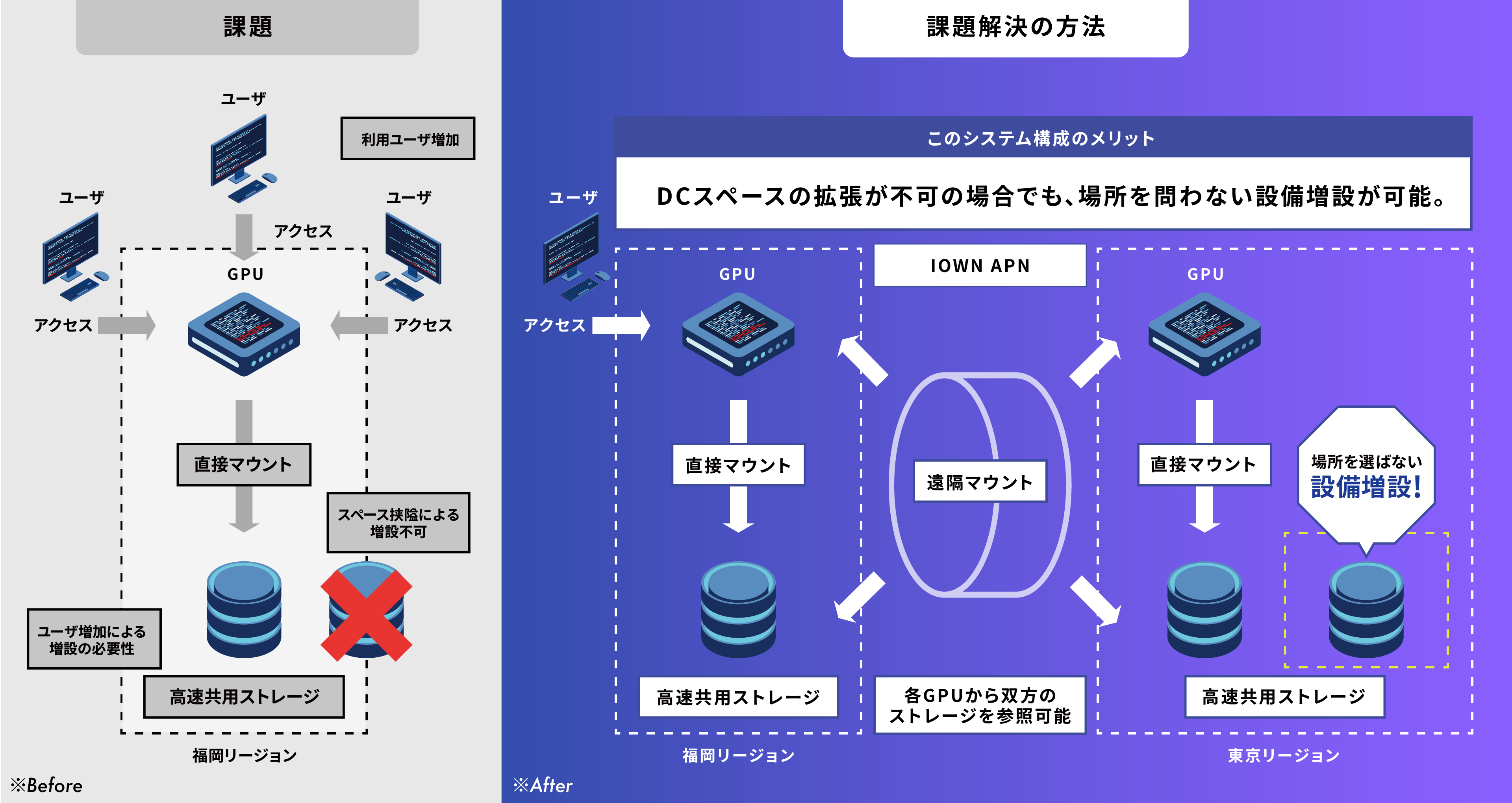
With the widespread adoption of generative AI and large language models (LLMs) in recent years, demand for AI development infrastructure has been rapidly expanding. Traditionally, GPUs and large-capacity storage have been required to be physically co-located. However, in order to address data center space constraints and the need to manage data within one’s own facilities, there is a growing demand for distributed AI development infrastructure that overcomes geographical limitations. The four companies have been exploring the technical feasibility of connecting remotely located GPUs and storage by leveraging IOWN APN, which offers high-speed, high-capacity, and low-latency characteristics.
▼Examples of challenges in building AI development infrastructure
Overview and Results of the Pre-demonstration (Phase 1)
In July 2025, a latency control device “OTN Anywhere” was installed in a data center in Fukuoka, and two test workloads—image recognition (ResNet) and language training (Llama2 70B)—were executed using GMO GPU Cloud. Under simulated latency conditions equivalent to Tokyo–Fukuoka (15 ms), it was confirmed that the benchmark score for ResNet decreased by approximately 12%, which was determined to be within a range acceptable for commercial use, leading to the progression to this demonstration.
Overview and Results of the Main Demonstration (Phase 2)
In this demonstration, as an actual inter-site network, GMO Internet Group, Inc.’s Group Second Headquarters (Shibuya-ku, Tokyo) and QTnet’s data center (Fukuoka City, Fukuoka Prefecture) were connected via IOWN APN (100GbE). A GPU server “NVIDIA HGX H100” was deployed on the Fukuoka side, and high-speed storage “DDN AI400X2” was deployed on the Shibuya side, and AI training performance when using remote storage was measured.
• Demonstration period: November 2025 – February 2026
• Connection section: Shibuya-ku, Tokyo (GMO Internet) – Fukuoka City, Fukuoka Prefecture (QTnet)
• Demonstration details: Measurement of training time for image classification tasks (ResNet) and large-scale language model processing tasks (Llama2 70B)
Results of the Demonstration
As a result of the demonstration, it was confirmed that even in a remote distributed environment via IOWN APN, performance comparable to that of a local environment (within the same data center) can be achieved.
■ Large-scale language model (Llama2 70B) training task
o Local environment: 24.87 minutes
o Remote environment (via IOWN APN): 24.99 minutes
o It was demonstrated that in LLM training, where computation processing is dominant, the impact of latency is extremely limited (approximately 0.5% difference).
■ Image classification (ResNet) task
o Local environment: 13.72 minutes
o Remote environment (via IOWN APN): 14.38 minutes
o It was confirmed that even for tasks involving data loading, practical-level processing is achievable in a remote environment through appropriate data formatting.
*The results of this verification have not been officially verified or approved by MLCommons Association.*
For details, please refer to the appendix below:
Details and results of GPU–storage connection performance tests in a remote distributed AI infrastructure utilizing “IOWN APN”
URL [https://internet.gmo/news/article/172/](https://internet.gmo/news/article/172/)
Transformations Brought by This Demonstration
The success of this demonstration marks a major turning point in resolving the challenge of “separating computing resources and data” caused by physical distance. Traditionally, data required for AI training has been transferred and duplicated to cloud providers’ data centers. However, the model demonstrated here—“keeping data in place while allowing computing resources to access it remotely”—presents a new option for fields with strict data sovereignty and security requirements. This is expected to enable reductions in data transfer time and costs, elimination of duplicate data management, and expanded flexibility in selecting computing resources through a combination of on-premise and cloud environments. In particular, this model, which allows the use of domestic cloud GPU resources while keeping data under the control of a company’s own facilities and organization, is expected to significantly contribute to the realization of “sovereign cloud” in sectors with strict internal controls and data sovereignty regulations, such as finance, healthcare, defense, and government.
Expected Use Cases
The practical application of the technologies validated in this demonstration is expected to enable the following use cases. However, in actual implementation, performance may vary depending on specific conditions such as the distance between GPUs and storage and network configurations, so it is necessary to evaluate applicability for each use case.
• AI training while retaining large-scale or sensitive data: Execute AI model training on remote cloud GPUs without storing or transferring data outside the organization’s controlled environment. • Hybrid utilization with existing on-premise environments: Build a flexible AI development environment by leveraging existing in-house storage and GPU resources while supplementing insufficient GPU capacity from the cloud. • BCP 대응 through geographically distributed deployment: Ensure continuity of AI processing during disasters or system failures by geographically distributing computing resources and storage to achieve a highly available environment.
This demonstration shows that IOWN APN is not merely a communication line but is evolving into a social infrastructure that supports AI and cloud platforms. The four companies will continue to promote the adoption of IOWN APN (NTT East and NTT West’s “All-Photonics Connect powered by IOWN”) and strengthen collaboration with cloud service providers such as GMO GPU Cloud, as well as regional data centers such as QTnet, aiming to establish IOWN APN as the backbone of AI infrastructure in society.
*The information and demonstration results presented in this press release are as of the announcement date. The content has been obtained under specific verification environments and does not guarantee equivalent performance or results in all environments.*
