

1. Overview of the Demonstration
1.1 Background and Purpose
In recent years, with the widespread adoption of generative AI and large language models (LLMs), demand for AI development infrastructure has expanded rapidly. Conventionally, AI computing devices (GPUs) and large-capacity storage have been considered to require physical proximity. However, in order to address various needs, such as space constraints in data centers and the desire to use GPU resources in domestic clouds while keeping data under the control of a company’s own facilities and organization, there is a growing need to realize remote distributed AI infrastructure that goes beyond geographic constraints.
In this demonstration, NTT evaluated the performance of GMO GPU Cloud between Tokyo and Fukuoka as a proof of the technical feasibility of remote use between GPUs and storage, leveraging the high-speed, high-capacity, and low-latency characteristics of the next-generation communications infrastructure developed by NTT, IOWN (Innovative Optical and Wireless Network) APN (All-Photonics Network).
1.2 Roles of Each Company
| GMO Internet, Inc. | Provision of GPUs and storage for GMO GPU Cloud Application implementation Provision of a demonstration environment within the data center (Shibuya-ku, Tokyo) |
| NTT East Corporation | Provision of IOWN APN technology and demonstration lines (*) |
| NTT West Corporation | Provision of IOWN APN technology and demonstration lines (*) |
| QTnet, Inc. | Provision of a demonstration environment within the data center (Fukuoka City, Fukuoka Prefecture) (*) |
1.3 Verification Schedule
Pre-verification: Performance evaluation in a simulated remote environment (conducted in July 2025)
Main demonstration: Connection verification between actual locations (November 2025 – February 2026)
Verification Environment and Configuration
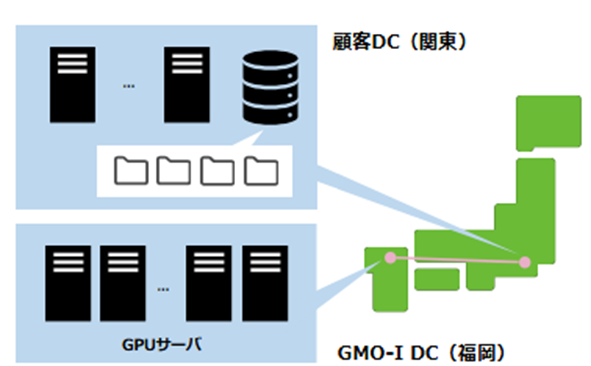
2.1 Physical Server Environment Configuration
・Location 1: QTnet Data Center (Fukuoka City, Fukuoka Prefecture)
●GPU: NVIDIA HGX H100
●Storage: DDN AI400X2
●Network switch: Arista 7050SX3-48YC8
・Location 2: GMO Internet Group, Inc. Group Second Headquarters, Shibuya Fukuras Server Room (Shibuya-ku, Tokyo)
●Storage: DDN AI400X2
●Network switch: Arista 7050SX3-48YC8
2.2 Network Configuration
• Line: All-Photonics Connect (100GbE)
2.3 Environment Construction Method
A GPU server (NVIDIA HGX H100) was installed in a data center in Fukuoka City, Fukuoka Prefecture, and storage (DDN AI400X2) was installed at Shibuya Fukuras, and they were connected via All-Photonics Connect powered by IOWN (100GbE).
In addition, for comparison, the same type of storage (DDN AI400X2) was installed in a data center in Fukuoka City, Fukuoka Prefecture and connected to the GPU server (NVIDIA HGX H100).
This enabled the construction of an environment for measuring storage performance across the IOWN APN network as well as within the Fukuoka data center.
Verification Scenarios
3.1 Test Workload
In this demonstration, representative image classification and language learning tasks in AI development, as well as performance measurements of the storage system, were
3.2 Image Classification Task: MLPerf® Training Round 4.0 ResNet (*1, hereinafter referred to as ResNet)
• Benchmark: ResNet (Residual Neural Network)
• Feature: Executes loading and processing of the ImageNet dataset (which contains approximately 1.28 million training images)
• Evaluation metric: Training time required to reach the target accuracy
3.3 Large-Scale Language Model Training Task: MLPerf® Training Round 4.1 Llama2 70B (*2, hereinafter referred to as Llama2)
• Benchmark: Llama (Large Language Model Meta AI) 2 70B
• Feature: Executes training on the Llama2 70B model itself (approximately 130GB)
• Evaluation metric: Training time required to reach the target accuracy
*The MLPerf results described in this document are unofficial (Unverified) and have not been submitted to or approved by MLCommons Associations.*
4. Experimental Results
4.1 Results of ResNet Image Classification Task
| Latency Condition | Benchmark Score (minutes)(*1) |
|---|---|
| Local Environment | 13.72 minutes |
| Remote Environment (via IOWN) (13.26ms) | 14.38 minutes |
| (Reference) Pre-verification Environment (15ms) | 15.55 minutes |
4.2 Results of Llama Large-Scale Language Processing Task
| Latency Condition | Benchmark Score (minutes)(*1) |
|---|---|
| Local Environment | 24.87 minutes |
| Remote Environment (via IOWN) (13.26ms) | 24.99 minutes |
| (Reference) Pre-verification Environment (15ms) | 24.94 minutes |
Analysis and Discussion
5.1 Performance Impact Analysis
In this demonstration (Phase 2), compared to the “simulated latency injection” used in the pre-verification, the IOWN network between actual locations was used to confirm performance impacts equivalent to real operations when using remote storage. As a result, the score trends for both ResNet and Llama2-70B were close to those under the 15ms condition in the pre-verification, leading to the conclusion that the IOWN network successfully reproduced performance under the intended latency conditions. The trend of score variation due to latency was also consistent with the pre-verification, and (for reasons described later) Llama2-70B showed a smaller degree of performance impact from latency.
5.2 ResNet Image Classification Task
As confirmed in the pre-demonstration, since the ImageNet dataset is loaded into GPU memory after the benchmark measurement begins, the task is highly susceptible to latency conditions, resulting in performance lower than the local environment but higher than the pre-demonstration, as expected. However, because the dataset to be loaded was preprocessed into a single file format that is easier to handle from raw data (approximately 1.28 million training images), resulting in large-block I/O, it is considered that the performance degradation remained relatively minor.
5.3 Llama Large-Scale Language Model Processing Task
As confirmed in the pre-verification, since the loading of the large-scale language model into GPU memory is completed before the measurement begins, most of the processing after the start of measurement is completed mainly by computations on the GPU. As a result, I/O to storage is significantly smaller compared to the ResNet image classification task, leading to only a minimal decrease in the benchmark score.
5.4 Summary
In this demonstration, results consistent with the pre-demonstration were obtained for both the image classification task and the large-scale language model processing task. As confirmed in the pre-demonstration, in training scenarios where loading large files is the primary operation, the performance degradation was minimal. This indicates that in machine learning using remote storage, by adopting a usage model in which existing training data stored remotely or preprocessed datasets are loaded into GPUs, it is possible to fully benefit from machine learning via remote storage.
For this demonstration, we would like to express our sincere gratitude to DataDirect Networks Japan Co., Ltd. for providing a DDN AI400X2 of the same model as the one owned by GMO Internet, Inc., which was installed at the Shibuya Fukuras site.
6. Vision for Future Social Implementation
Traditionally, computing resources and data (storage) have generally been located in the same place (data center), and when using computing resources located remotely, such as cloud services, it has been common to copy or transfer files to the cloud environment. However, by remotely accessing storage from computing resources via the IOWN APN network and directly reading data, these processes become unnecessary.
The results obtained from this demonstration make it possible to resolve the issues arising from the separation of computing resources and data:
● Reduction in data transfer time
● Elimination of duplicate data management
● Flexible selection of computing resources
However, in actual application, performance may vary depending on individual conditions such as the distance between GPUs and storage and network configurations, so it is necessary to evaluate applicability for each use case.
Furthermore, by widely deploying IOWN APN (NTT East and NTT West’s “All-Photonics Connect powered by IOWN”), the following social contributions can be expected:
1. Realization of a distributed AI development infrastructure: Optimal allocation of AI resources on a nationwide scale through hybrid use of existing on-premise environments and cloud
2. Improved disaster resilience: Ensuring business continuity through distributed deployment
※1 Unverified MLPerf® Training Round 4.0 Closed Resnet offline. Result not verified by MLCommons Association.
※2 Unverified MLPerf® Training Round 4.1 Closed Llama2 70B offline. Result not verified by MLCommons Association.
The MLPerf name and logo are registered and unregistered trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.”
The information and demonstration results presented in this document are as of the announcement date. The content has been obtained under specific verification environments and does not guarantee equivalent performance or results in all environments.
